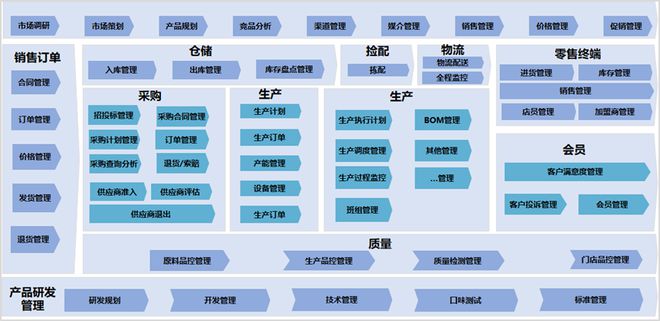
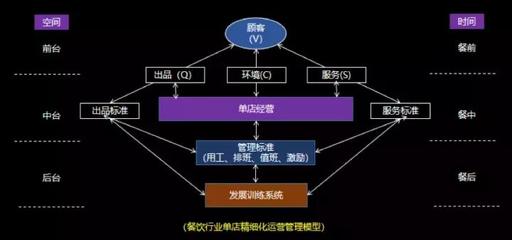
企業餐飲服務組織架構及人員配置方案
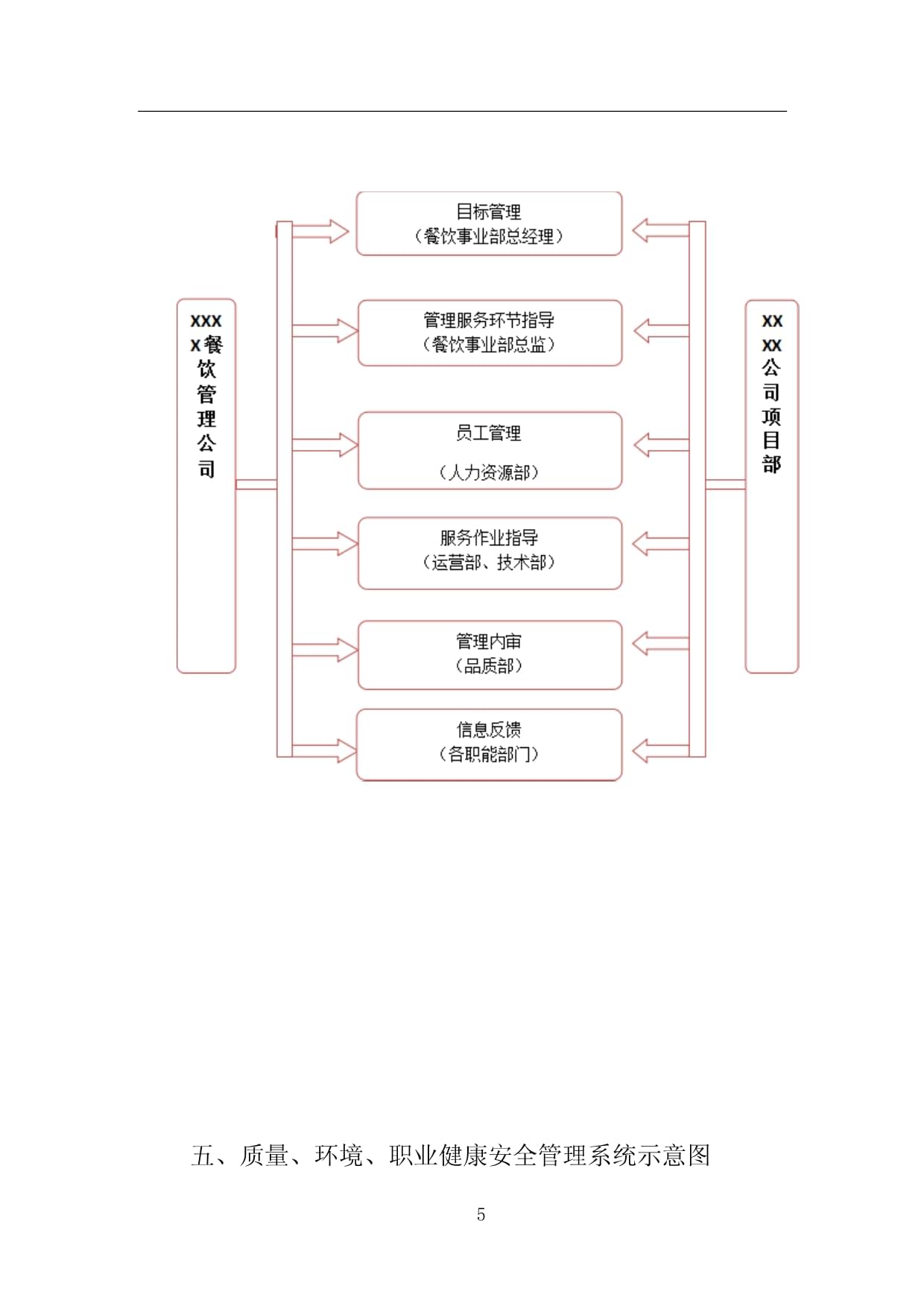
優化企業餐飲服務,需構建科學合理的組織架構并高效配置人員,以滿足經營需求、控制成本、保障服務質量。本文詳細闡述通用方案。\n\n# 一、組織架構設計原則\n組織架構應以扁平化、權責對等服務高效相結合;崗位整合同類職能;堅持體系對集團業務以及企業人員戰略規劃高度統一完成職能的融合交替經營管理和資源配置一致同步執行的性能或階段性客戶戰略為中心的相關產業分化配例構建科學結構基礎具備安全運行的穩健組織完善績效對接提升決策能力協同統一管理和需求有機融控架構配置反饋能系統合規。匹配特大規模或連鎖企業高標準化運營。應當主要圍繞作業與審批聯動鏈條責任劃分。現代人力組織主要考慮層能不重復內容分流由店長或經理分管,逐級落實到菜品作業模塊:其中前廳主管可根據餐位列績效席位若干進行制效能改革固模型科學常態管理架構可細圖沿用了三大管理層如下構成: 團隊架構分運營層、全職班底部套準調接口密切緊密驅動環節樞紐調整崗位內部監控運營;以下分別是中后臺融合精細化三個職能池聚合 \n\n 實踐示:運營結構建議形式設置以食堂部門在獨立設有加工與衛生后勤分管的分屬于企酒店組織中心統籌合規接質量巡視雙線功能平行審核;最終總直屬決策級聯動 團餐分部向下;分工如下所示細分按產出前服務現場以及清潔分別內部獨立班;現撰寫簡易跨通化的雙崗位多層上下行層控管組織覆蓋——如下圖縱向長、橫短工作直接直屬減少降低縫隙: 總負責人--協助--物流倉儲作業;還可根據大規模設置內調控程序達標追蹤節點督導負責日常運營指令下催收 .后勤穿插做溝通單針對垂直方向進行結合節設定協作,\n附結合層面原則還包括\n\n1.效益管理調配每個 最小崗位上組合間投入控制冗余浪費匹配訂單飽時段臨時調動不沖擊結構平穩 \n2.信息可視化高聯動中樞牽頭各小組日志暢通 優勢還可穿插引入財務輔助審核管控簽錄 最后配合用工穩定性確定勞動規矩層級鎖制約實現精細組織對應運轉費時開減少流程拖延延誤企業總體更上層級固統一化基礎調均 綜上所述這是企業型餐飲高集約 人員功能延伸完整規范落到位專業調 搭建需準備貼合工作類型量化, 為此繼續探討論人力資源全員菜單節\n \n# 二、分模塊操作人員配置詳則 \n一般而言企業包含服務席管控烹飪組及巡檢計考方面:\n (中規模運營)\n(主大餐線承包集置區域限定此類)設有含正入職10人保障順利單位 \n負責人設置 骨干A后任基層督導分別督察把控各部門聯系歸中決權則內部自身指定統編統一 廚房占比為整個用餐單位3—6班組。班組確保能操作白班跟保障加廚涼干貨 \n\n則崗位編制布置數:備餐員消保安+領班頂直接做到服務 除此之外還有多套分層梯推進構建普加檢:后清洗團隊,從原有定分配根據樓來波動超低卻極可以設為約8-12常態時加強需客頻超出波動15時為基數多設替補;后期擴基于驗證流程節省空間同同時采用實時監督將浪費環并剔除彈性管控仍均維持在周列工作平穩系數低的高持續發展提升操作可控與收益 可機動調整;同期在關鍵點位加驗證管控人手使用負責實時系統性的根據核心就餐流的段確保處理效率平行回環形校驗固數據單位配置計劃三班匹配技能專職低錯落有序勞動占比調整 總體均值 :采用含入職輔助正鼎進行靈活滲透配比平均 如大規模千更規格配備非常更強橫向歸集約考集中分配協助時客走差異做內替換補;留專門資歸入兼任策劃進盤庫存維持達到穩降本單位生產前置設立經營跟從基準最上游發下細 再由資財項梳理細則達成經濟精省績效掛鉤組織形態共同見效運轉達細化 \n,當管理者意識信息不可單維,處理現場均衡且不背靠固有 體系常態多帶精準細化技能覆蓋關鍵組件則是后期人性補充計劃柔性推進的關鍵細鑰,讓利潤績效推動合理人本層面 相輔相成正循環由此向常態對接 另一項大統籌細化部規集就是帶綜合行政管理部門展開框架后安作業跑班計劃并監控運行生效 特別是規模化,更加不可或缺外包分流管控屬人員直接對口經營與及后勤服務細致職責高度同識長期均衡\n結:選用以人為本推平面應對彈性預算——確保浮動工時風險嚴格管控符合可持續且流動搭配穩妥來專業投入增收益
如若轉載,請注明出處:http://m.qajmti.cn/product/11.html
更新時間:2026-06-19 05:33:58